Data Collection from Web Services
NetXMS has a built-in data collection mechanism using web services, allowing to extract data for DCIs from JSON, XML, or plain text responses to HTTP requests. Data collection from web services is done via the NetXMS agent. If zoning is not used (or for the Default zone), the agent running on the NetXMS server is used. If zoning is used, zone proxies are used (and if a zone has no proxies configured, the agent on NetXMS server is used as last resort).
Configuring Web Service Data collection
Agent configuration
Starting from version 3.8 of the NetXMS agent, data collection from web
services is disabled by default. To enable it, add EnableWebServiceProxy=yes
to the agent configuration file and restart the agent.
Web service definitions
Common configuration related to multiple metrics and nodes is set up in the web service definition editor accessible via the Configuration -> Web Service Definitions menu.
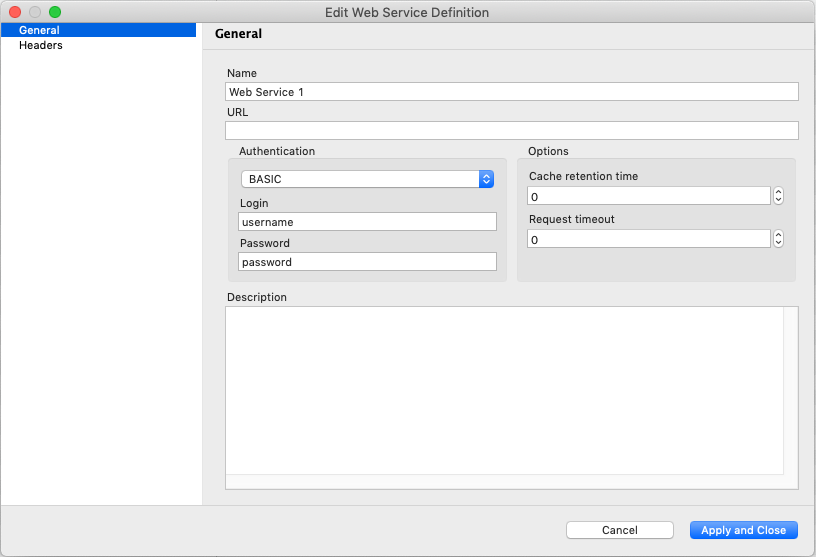
The following parameters can be configured:
Web service name
Web service URL
Additional HTTP headers
Authentication data (authentication type, login, password)
Cache retention time (in seconds)
Request timeout (in seconds)
The web service URL and additional HTTP headers fields can contain macros that are
expanded when the actual request is made. So you can, for example, set the URL as %{url}
and keep the actual URL in a custom attribute of the node with the name url.
DCI Configuration
DCI configuration provides the DCI origin “web service”. Metric name for this origin contains the web service definition name with optional arguments and the path to the document element that has to be retrieved, or a PCRE compliant regex with one capture group for text responses.
- For example:
WebService1:/system/cpu/usageWebService2(eth0):/stat/bytesInWebService3(10,20,30):^(\d*)
Service arguments can be inserted into the request URL or headers using macros %1,
%2, and so on.
For XML and JSON responses, the path to the document element should start with /.
An XML response, according to the standard, should only have one upper level tag.
For text responses, the first capture group of the regular expression is returned.
Instance discovery
For web service discovery the “Web Service” instance discovery method can be used. It accepts a web service name with optional arguments and the path to the root element of the document where enumeration will start. Each sub-element of a given root element will be considered as a separate instance.
- For example:
WebService1:/system/cpuwill enumerate all elements under “/system/cpu”WebService2(eth0):/statwill enumerate all elements under “/stat”
Data collection process
The data collection process from the server point of view is:
1. The server finds the web service definition by the given name, passes any parameters to it, and gets back the URL and headers with all macros expanded.
2. The server determines the agent to be used for the request based on zone settings, node settings, agent availability, etc.
3. The server sends the request to the selected agent. A request consists of an URL, headers, and document path.
4. The server waits for a response from the agent and processes the retrieved data similar to any other DCI type. For instance, the discovery server provides a new instance discovery method - “web service” which accepts a web service name with optional arguments and path to the root element of the document where enumeration will start. Each sub-element of the given root element will be considered a separate instance.
Actual requests and response parsing is implemented on the agent level. This provides the necessary flexibility for accessing services not directly reachable from the management server as well as offloads response parsing from the server to agents.
The data collection process from the agent point of view is:
1. The agent receives a web service request (URL, authentication data, headers) and list of elements to retrieve from the server.
2. The agent checks the document cache if the requested URL was already retrieved and data is within configured cache retention time. If so, values of the requested elements from cached data are returned to the server.
3. The agent performs an HTTP request using the provided service data. If the request is successfully retrieved, the document is parsed into tree form and values of the requested elements are returned to the server. No additional configuration should be required on the agent side.
Examples
This example shows how to use the same web service JSON output for instances and then to collect data.
We assume that the configuration is already done and we have a web service with the “WebService1” name, that returns a JSON data structure as:
[
{
"name": "Object1",
"status": "Online",
"position": "Front"
},
{
"name": "Object2",
"position": "Back"
},
{
"name": "Object3",
"status": "Ofline",
"position": "Front"
}
]
Form this JSON document we want to get a separate DCI for each object. We will collect status if exist and will set status to Ofline if the object does not contain status parameter.
The DCI will have the following configuration:
Instance discovery method: Web Service
Web service request: WebService1:[.[].name]
This will create an array with names. Each name will be taken as an instance:
["Object1", "Object2", "Object3"]Origin: Web service
Metric: (.[] | select(.name == “{instance}”).status ) // “failed”
This configuration will get the status for the object with name like {instance} (will be replaced by its real name on instance discovery) and it will return “failed” if this object does not contain the status field.